Spark Streaming实时日志处理
@
暴走漫画
@
暴走漫画
徐晓孟
2016-03-26
Spark简介
需求与思路
架构与实现
建议与展望
Spark
Spark是一个高效的
分布式计算系统
分布式计算系统
性能比传统上的Hadoop MR高
100倍
100倍
并且提供更加顶层的API
编程易于上手
代码量更少
代码量更少
what does Spark do is
what you want to do
what you want to do
使用原生JavaScript:
var str = "what does Spark do is what you want to do".split(' ');
var result = {};
var word;
for (var i = 0; i < str.length; i++) {
word = str[i];
result[word] = result[word] ? result[word] + 1 : 1;
}
console.log(result);
| Map |
word
=>
(word: 1)
|
| Reduce |
(word1: 1, word2: 1)
+ (word2: 1, word3: 1) =>
(word1: 1, word2: 2, word3: 1)
|
var result = "what does Spark do is what you want to do"
.split(' ')
.map(v => new Object({[v]: 1}))
.reduce(function(v1, v2) {
for (word in v2) {
v1[word] ? v1[word] += v2[word] : v1[word] = v2[word]
}
return v1;
});
console.log(result);
使用Spark API
var result = "what does Spark do is what you want to do"
.split(' ')
.map(v => [v, 1])
.reduceByKey((a, b) => a + b);
console.log(result);
需求与思路
ELK
优点:框架成熟,部署方便。
缺点:无法处理复杂的分析,配置辣么麻烦。
优点:框架成熟,部署方便。
缺点:无法处理复杂的分析,配置辣么麻烦。
=>
Spark Streaming
优点:可以应对复杂分析,没啥配置。
缺点:技术债务,成本。
优点:可以应对复杂分析,没啥配置。
缺点:技术债务,成本。
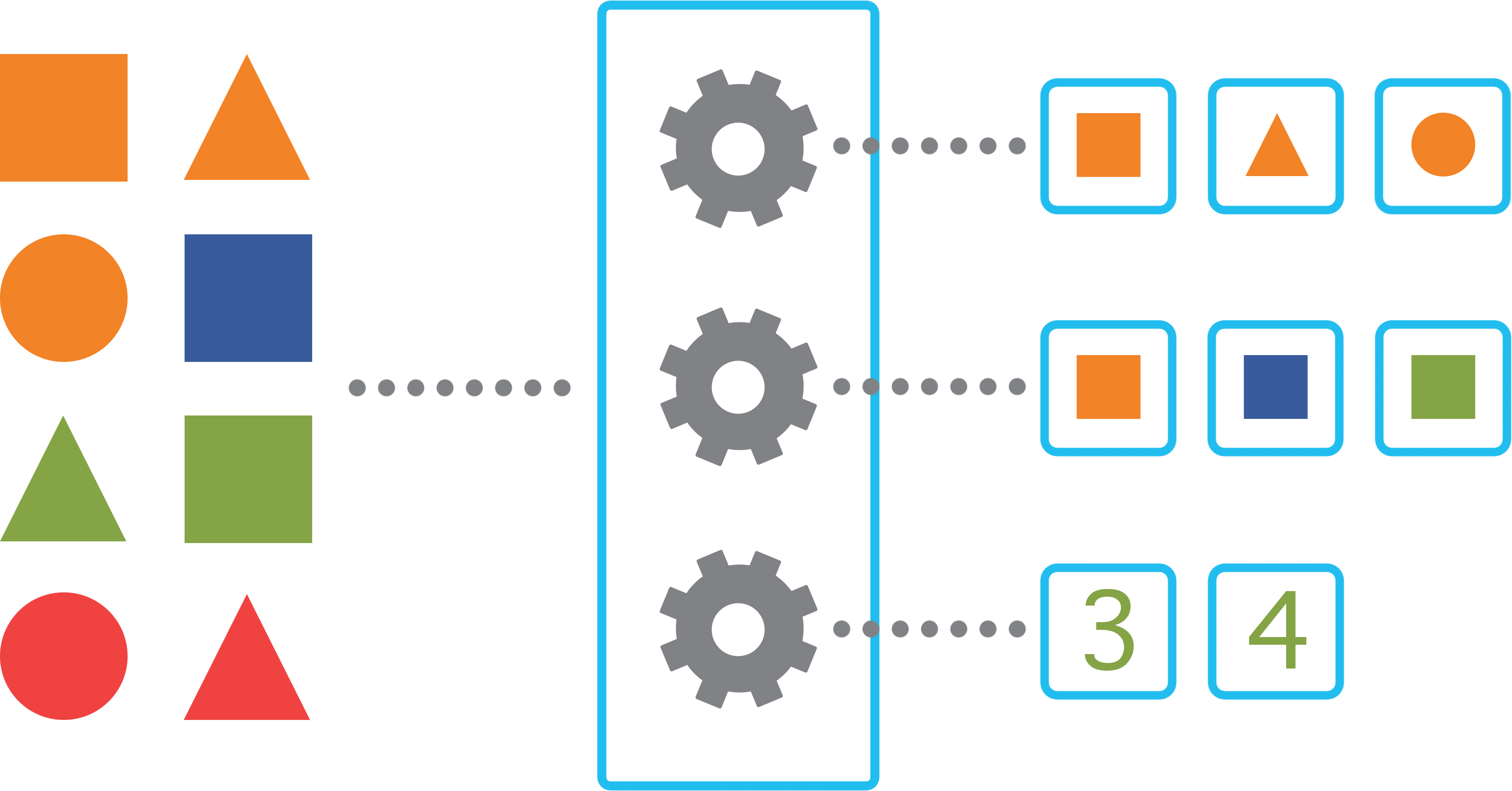
适配
对于每条日志,如果它同时符合N个适配条件,那么就会输出N个相应的处理结果;如果一个都不符合,则直接被丢弃。
条件
适配条件多种多样(特定字段值,正则匹配URL值等),应用提供最基本的类来支持最基础的匹配,也可以重载适配函数。
转换
每个适配器将对匹配的原始日志进行处理,并输出相应的处理后日志,按照指定格式存入数据库。
架构与实现
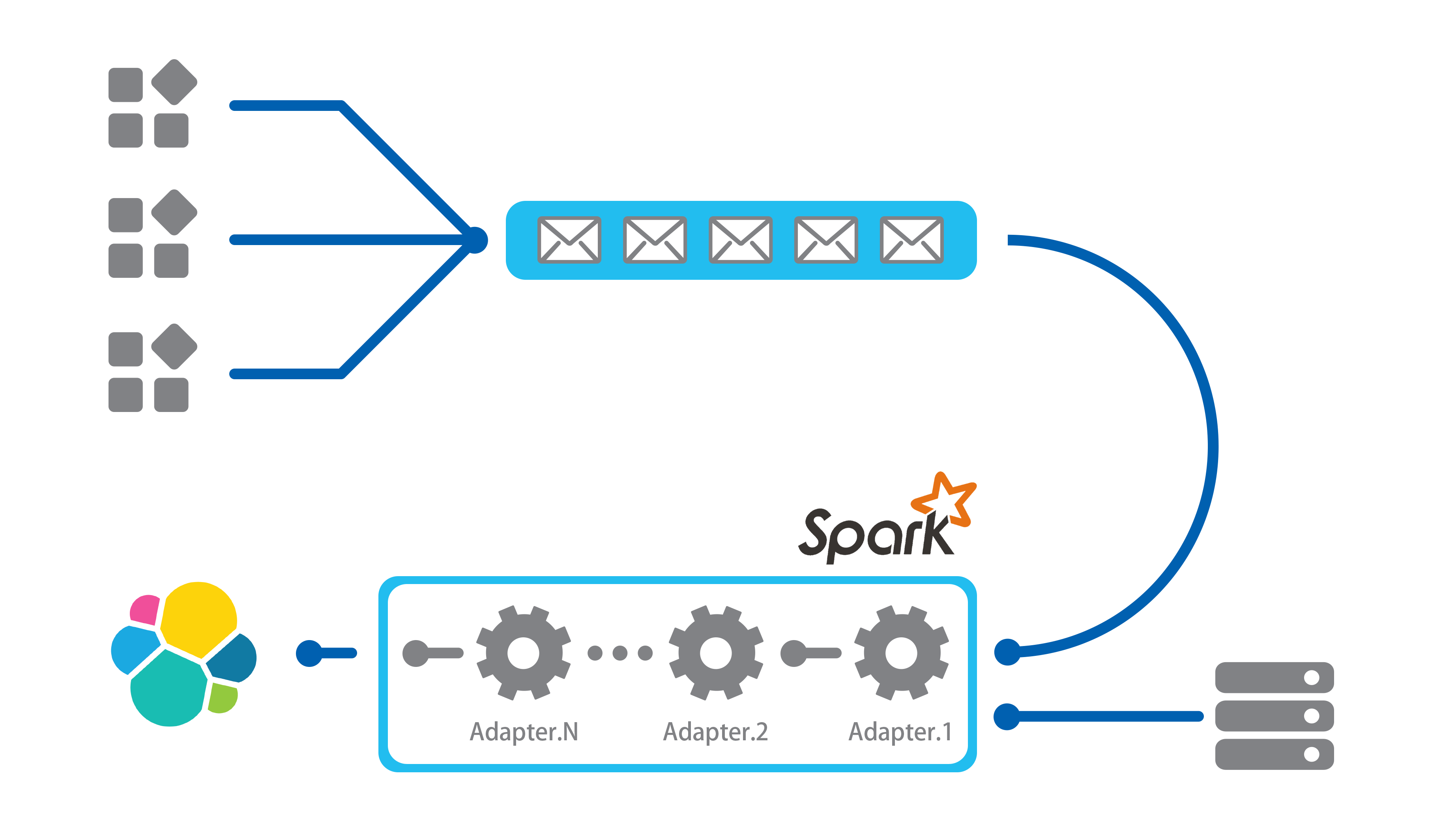
日志收集
在应用端使用Logstash监听日志,并将获得的日志分流——存储一份基础日志到ES,并复制一份进入消息队列。Logstash自带日志分析,然而需要处理的日志种类日益增多,并且更加复杂,那么编写Logstash配置将成为巨大挑战。
消息队列
我们使用Kafka作为消息队列,这可以使得应用获得一部分缓冲,若处理速度跟不上消息增长,那么则预示着可能需要增加计算资源。
获取数据
原始Log是Json格式的,它们将以2秒每批次的速率进入Spark计算集群。
Spark Streaming会对每一批次尽可能多地获取数据。
Spark Streaming会对每一批次尽可能多地获取数据。
Spark Driver
此结点作为Spark Driver存在,并不参与运算,它负责统筹运行状态,记录应用本身log,并向Spark Master申请计算资源。Spark Master将从此结点获得任务程序、依赖库以及静态文件,并在集群中分配Spark Executor进行计算。
日志分析
应用对Spark Streaming集群制订了窗口,窗口将会每隔10秒对未处理任务进行处理,这是除了消息队列之外的另一个弹性设定,它将降低Spark集群访问数据库的频次,如果一个窗口处理时间超过了10秒,那么任务会被顺延到下一个窗口,高峰期的任务会逐渐累积,并顺延至低谷期,若低谷期的算力仍然不足以处理任务,那么可能就需要调整Spark资源规模。Spark拥有Web UI,能详细到每一个任务的每一步运算,这对24*7任务的排错和监控具有非常好的指导作用。
日志适配器处理日志的原理是去匹配日志的一些特征,若符合一定规则,则认为是目标日志,将对这条日志进行分析,并输出新的日志。
|
|
日志存储
输出日志遵循了Logstash规范,使得输出到ES集群的处理后日志可以直接使用Kibana查看,或者提供后续程序做进一步处理或查询聚合使用。
建议
| 立项 | 在服务器资源少量的情况下,不要尝试使用Spark代替常规运算程序,Spark将会花费大量的时间在资源调度和IO上,服务器也有部分资源需要供给JVM和GC。 |
| 编码 | 时刻牢记程序将运行在分布式环境下,不要随意传递对象给函数,这有时候会导致程序在单机时可以运行,集群下运行失败。也要慎用广播,序列化编解码过程将花费大量时间。 |
| 重构 | 改进程序本身永远比无脑扩展集群规模要有效得多,熟练组合使用Spark的各类RDD转化和动作将大大减少运算时间。 |
| 维护 | 注意使用Web UI查看程序错误,也要定期关注集群健康度,必要时扩展集群规模。可以使用Ganglia之类的集群监控系统对结点健康状况进行监控。 |
如果发现Spark并不适合你的项目,需要有壮士断腕的勇气!
要知道Spark程序重构为普通程序是十分容易的,反之亦然。
要知道Spark程序重构为普通程序是十分容易的,反之亦然。
展望
- 输出数据到队列,将ES index分流工作交给后续程序,例如logstash。
- 支持热加载适配器。
- 将适配器写成描述性的配置文件而非代码。
- 支持类SQL语句生成简单的适配器。例如:
SELECT parameter.col AS col_out, sum(arr) AS sum_out FROM SOURCE WHERE path LIKE @'(/api/v\d+|)/videos/(?<video_id>\d+)/view/?'
Thank you :)
Powered By fairy.js
Powered By fairy.js